Multivariate Probability Calibration with Isotonic Bernstein Polynomials
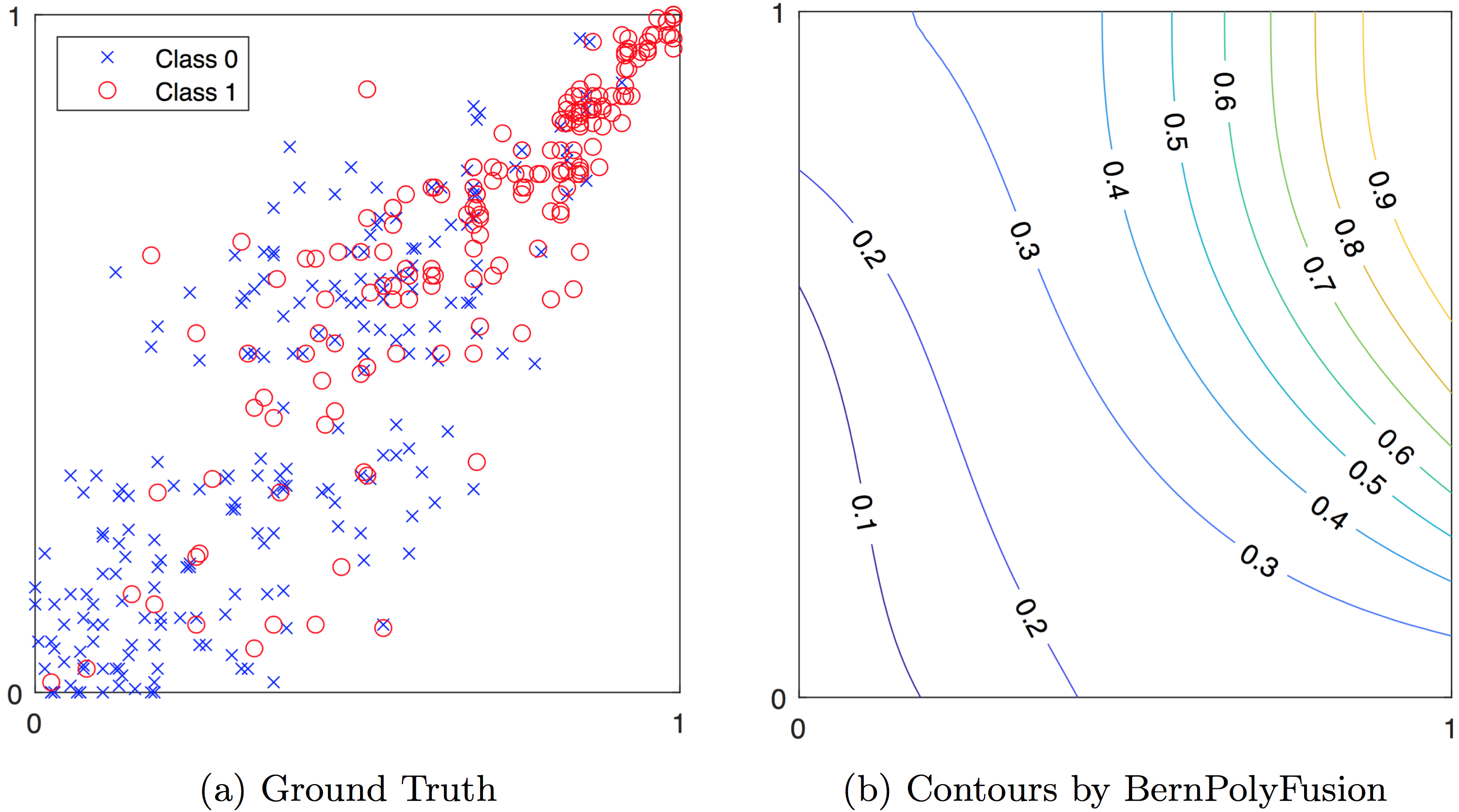
Multivariate probability calibration is the problem of predicting class membership probabilities from classification scores of multiple classifiers. To achieve better performance, the calibrating function is often required to be coordinate-wise non-decreasing; that is, for every classifier, the higher the score, the higher the probability of the class labeling being positive. To this end, we propose a multivariate regression method based on shape-restricted Bernstein polynomials. This method is universally flexible: it can approximate any continuous calibrating function with any specified error, as the polynomial degree increases to infinite. Moreover, it is universally consistent: the estimated calibrating function converges to any continuous calibrating function, as the training size increases to infinity. Our empirical study shows that the proposed method achieves better calibrating performance than benchmark methods. Related: IJCAI-20 paper.
Clustering Partial Lexicographic Preference Trees
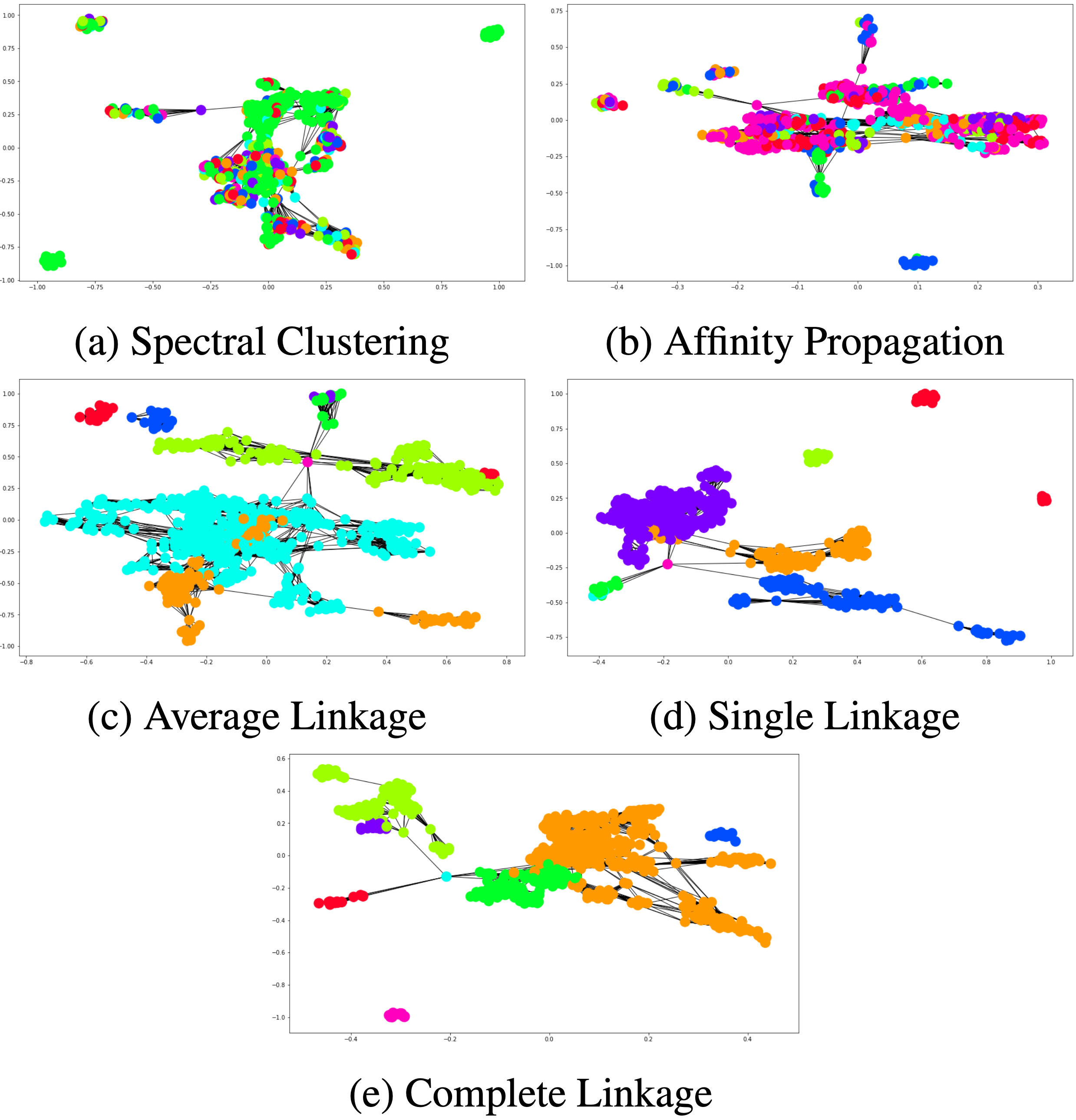
Due to the preordering nature of PLP-trees, we define a variant of Kendall’s τ distance metric to be used to compute distances between PLP-trees for clustering. To this end, extending the previous work by Li and Kazimipour (Li and Kazimipour 2018), we propose a polynomial time algorithm PlpDis to compute such distances, and present empirical results comparing it against the brute-force baseline. Based on PlpDis, we use various distance-based clustering methods to cluster PLP-trees learned from a car evaluation dataset. Our experiments show that hierarchical agglomerative nesting (AGNES) is the best choice for clustering PLP-trees, and that the single-linkage variant of AGNES is the best fit for clustering large numbers of trees. Related: FLAIRS-33 paper.
Human-in-the-Loop Learning of Qualitative Preference Models
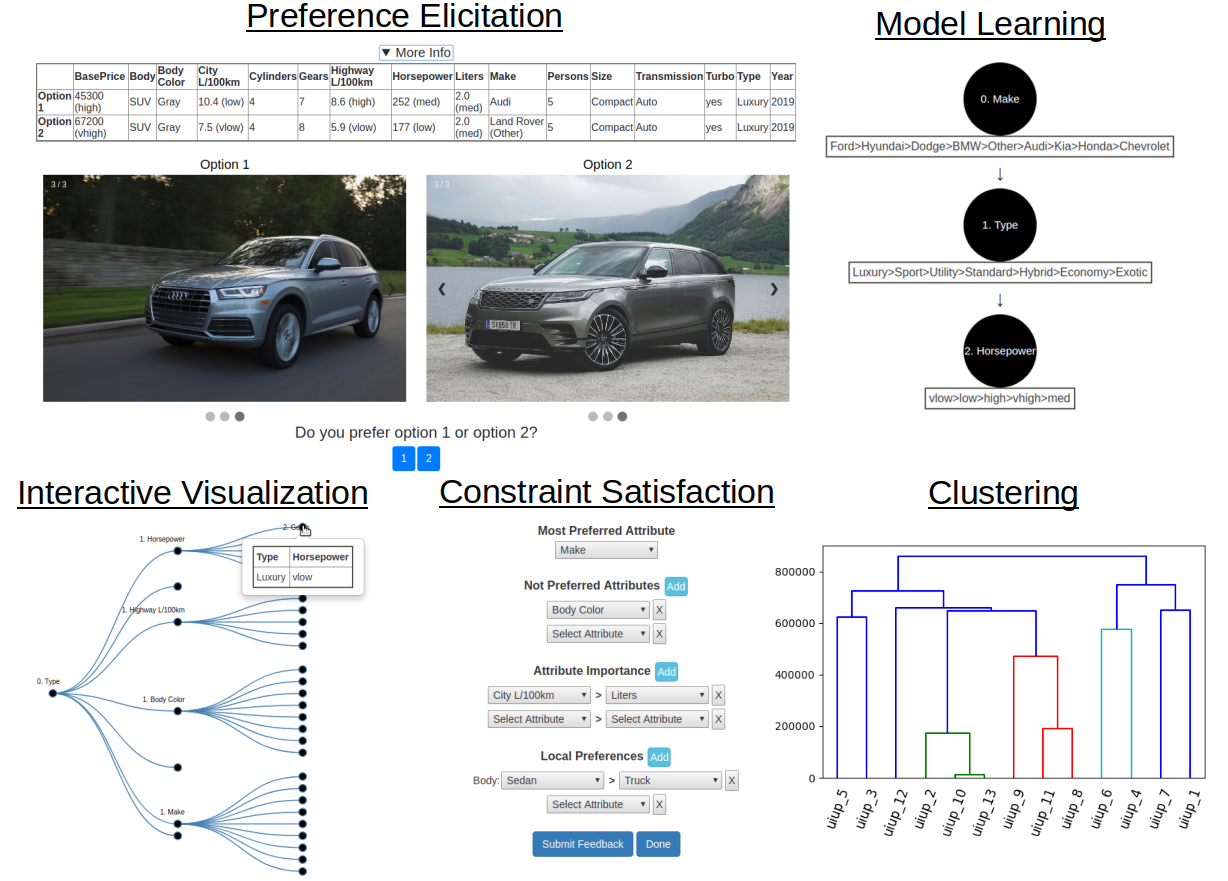
We explore visual analytics for preferences, active/online learning of preference models, visualizing forests of partial lexicographic preference trees through clustering, automated feature extraction from object images, and transfer learning to support cross-domain recommendations. Related: FLAIRS-32 paper.
Vegetation Coverage in Marsh Grass Photography
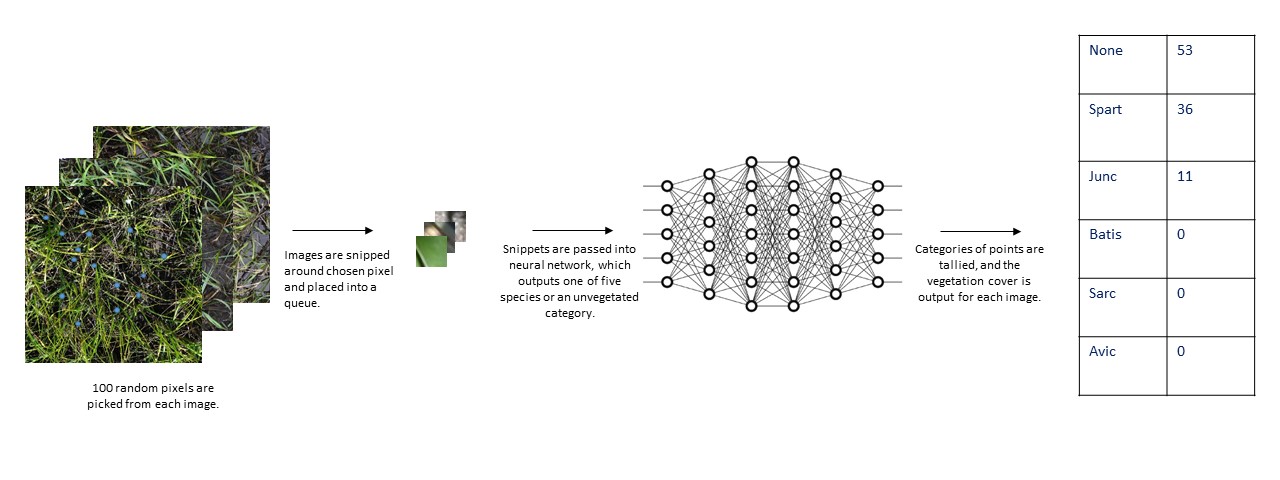
Using deep neural network models, we try to automate the process of determining the percentage of the marsh coverages for various species of vegetation. Dataset: here.
Parallel Machine Learning Using Serverless Architecture
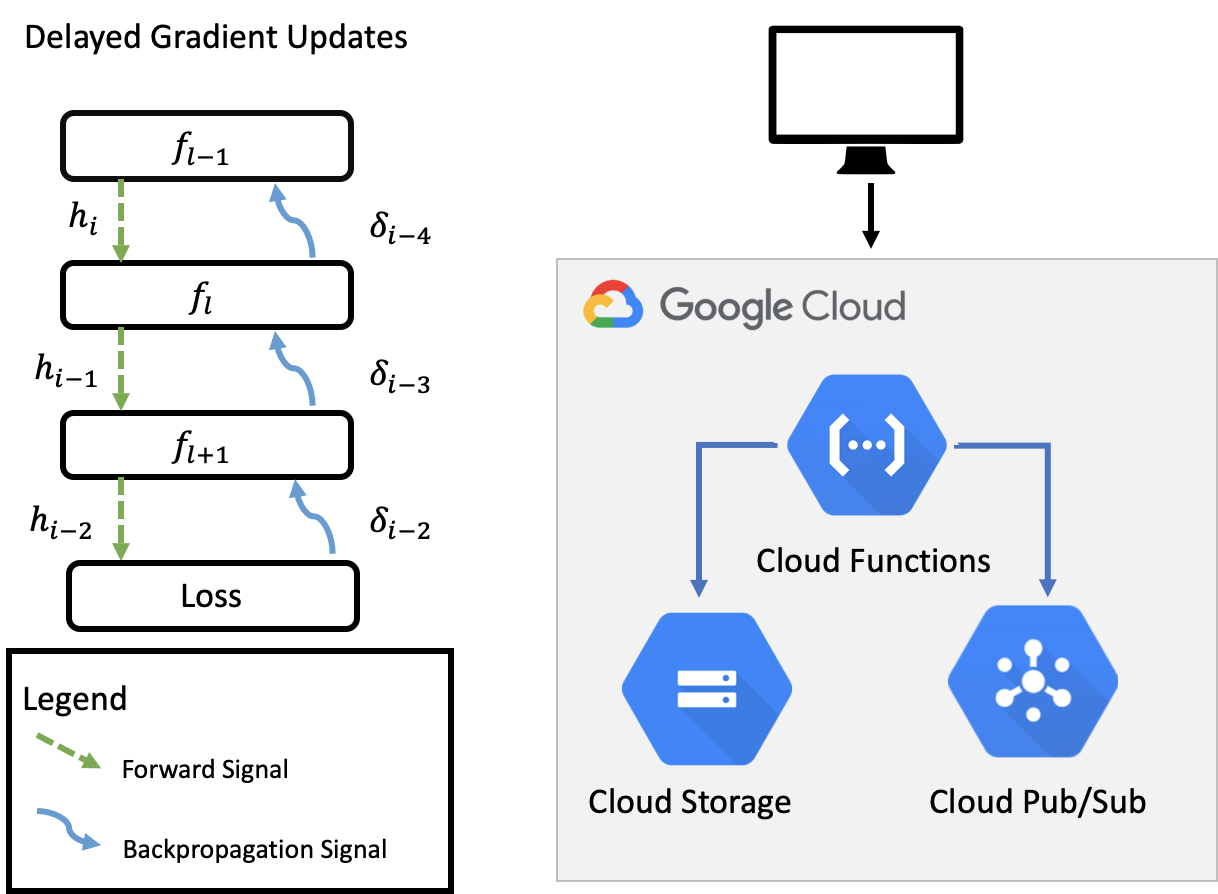
We design and implement a parallel framework for machine learning models that are deployed to cloud-based serverless platforms. This framework aims to accelerate the training of large scale models through the utilization of dynamically allocated resources.
Human-in-the-loop Preference Learning
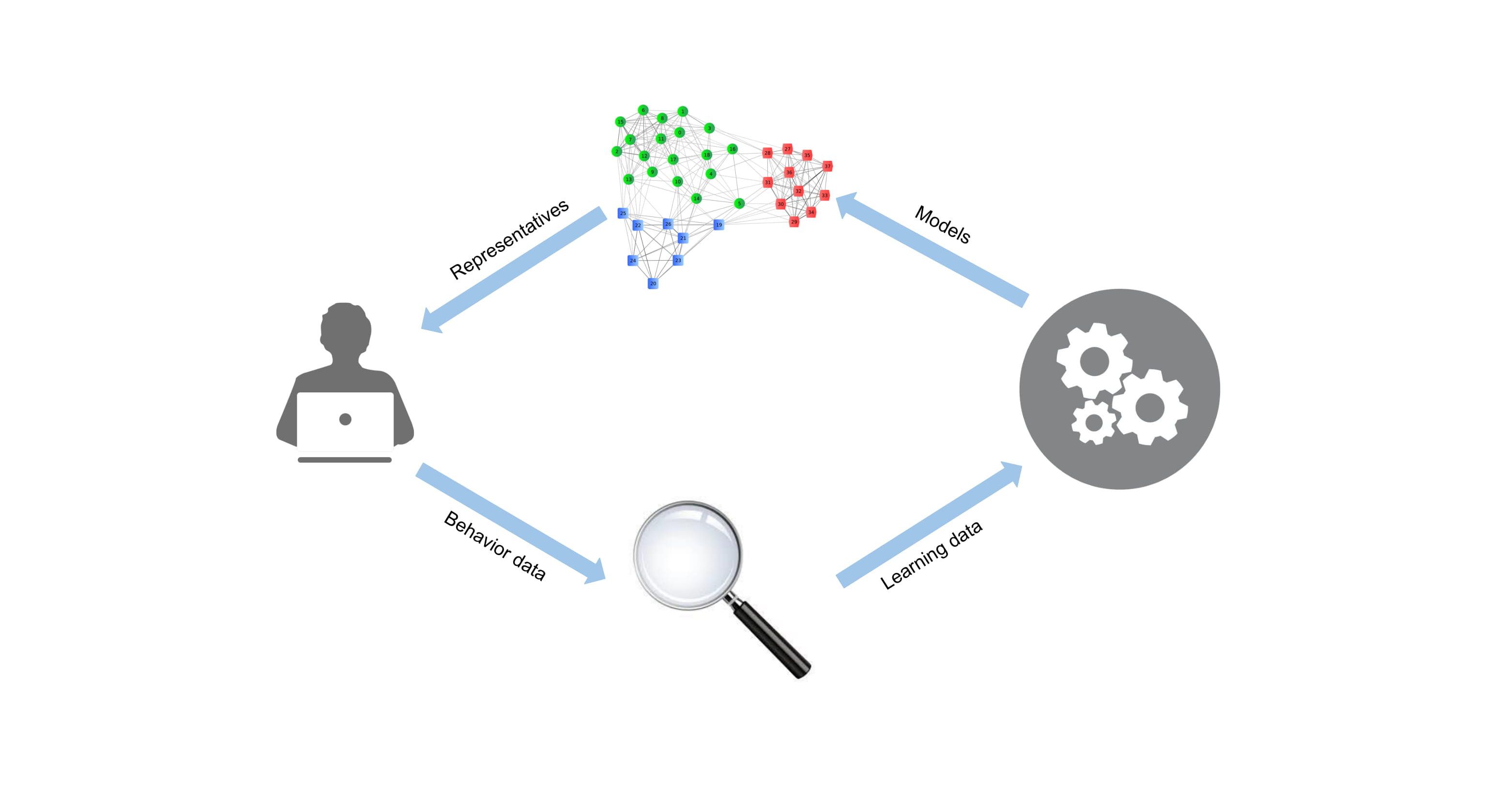
We design and implement a decision analysis system using interactive learning to learn interpretable predictive decision models (e.g., lexicographic preference trees and conditional preference networks) to provide insight into agents' decision making process. Related: FLAIRS 2019.
Smart Transportation
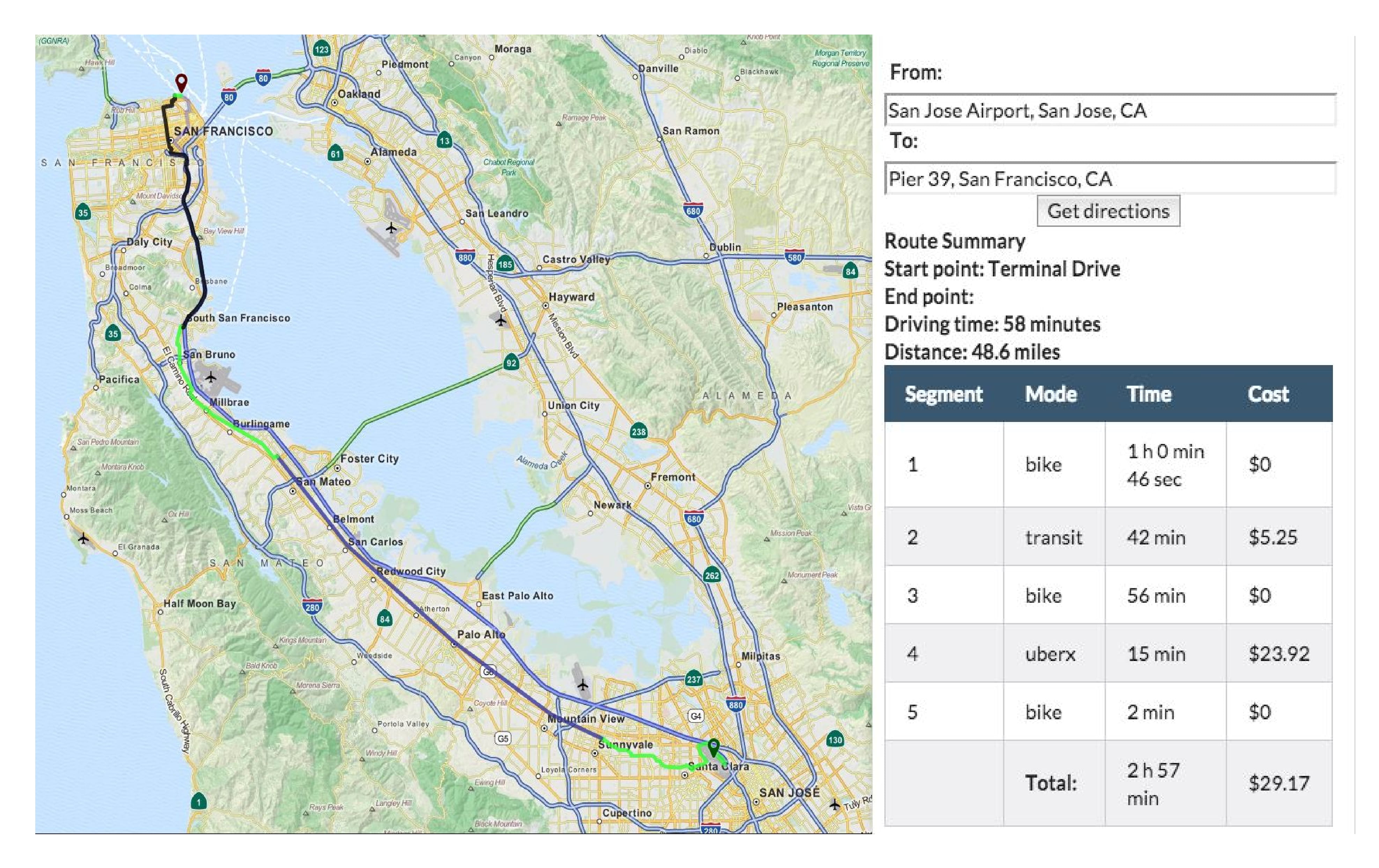
We designed and developed a smart multi-modal transportation planner that allows user-specific metrics (e.g., crime rates and crash data), to specify constraints as a theory in the linear temporal logic, and to express preferences as a preferential cost function. In the demo, an optimal trip is computed for Alice who doesn't have a car but has a bike, and she wants to bike at least 1 and at most 2 hours. Moreover, she prefers biking and public transits over uber. Related: FLAIRS 2019.